Einstiegsanleitung: Neuro-Simulationen mit Python und Nengo¶
Liebe TeilnehmerInnen,
da wir nicht nur über Gehirn-Simulationen diskutieren wollen, ohne sie selbst kennen gelernt zu haben, möchten wir im Rahmen der Frühjahrsschule auch zeigen, wie man einfache Neuro-Simulationen selbst programmiert. Genau genommen werden wir das nicht nur zeigen, sondern Ihr werdet selbst programmieren. Da vermutlich nicht jeder von euch schon ein Computerprogram geschrieben hat und nur einige von Euch ein technisches Fach studieren, soll das in Gruppen geschehen, so dass in jeder Gruppe mindestens ein "Techniker" oder eine "Technikerin" mit Programmier-Vorkenntnissen ist. Trotzdem sollten aber auch die anderen versuchen, die Simulation mitzugestalten und mitzuprogrammieren.
Um den Einstieg zu erleichtern, ist diese Einführung gedacht. Wir setzen nichts voraus, nicht einmal elementare Programmierkenntnisse. Wer schon welche hat, kann einfach die entsprechenden Abschnitte überspringen.
Viel Spaß!
Die Python-Programmiersprache installieren¶
Wir verwenden für unsere Simulationen die Programmiersprache Python, eine sehr leicht zu erlernende, aber dennoch überaus leistungsfähige Sprache, die gerade im Bereich des wissenschaftlichen Programmierens (scientific computing) überaus populär ist.
Python installieren¶
Um die Programmiersprache Python zu nutzen, müssen wir zunächst einen Python-Interpreter herunterladen und installieren. Es gibt dabei mehrere unterschiedliche Pakete mit einem größeren oder kleineren Umfang. Wir empfehlen das Anaconda-Paket, da ist schon fast alles bei, was wir brauchen. Hier könnt ihr Anaconda für Linux, Mac oder Windows herunterladen:
Wer Linux verwendet und lieber seinen Linux-Paketmanager benutzt und dort anaconda nicht findet, der sollte außer pyhton3 auf jeden fall die Pakete numpy, matplotlib und jupyter herunterladen.
Installation testen¶
Ist alles fertig installiert, dann können wir, um die Installation zu testen, ein Python-Notebook öffnen. Dazu müssen wir unter Windows im Start-Menü Alle Apps -> Anaconda -> Jupyter notebook aufrufen. Alternativ könnt ihr den Anaconda Command Prompt öffnen und dort jupyter notebook D:/meinpfad/meinordner eingeben. Unter Linux kann man auf der Kommandozeile jupyter notebook eingeben und bei MacOS findet Ihr es am besten selbst heraus.
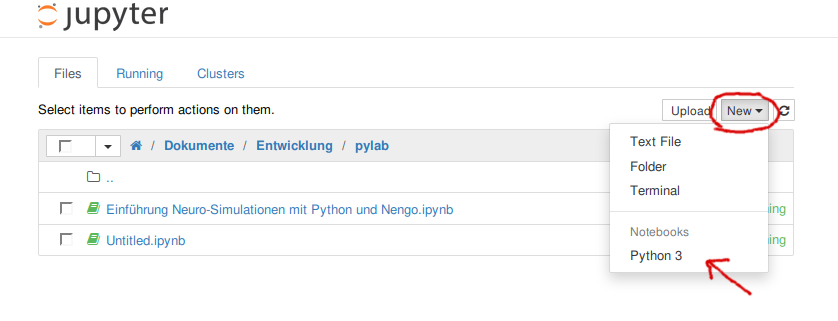
In jedem Fall sollte sich dann ein Browser-Fenster mit einer Seite öffnen, auf der oben Jupyter steht und das vermutlich Euer Heimatverzeichnis anzeigt. Rechts befindet sich ein kleiner Knopf mit der Aufschrift "New" und einem nach unten gerichteten Dreieck, der ein Menü öffnet, in dem ihr den letzten Punkt, nämlich Python 3 unter "notebooks" wählt, um ein neues Python-Notebook anzufangen, das sich dann in einer neuen Registerkarte des Internet-Browsers öffnen müsste. Rechts neben Python 3 sollte jetzt ein kleiner Kreis zu sehen sein, der anzeigt, dass das Notebook korrekt arbeitet. Ist das nicht der Fall könnte es sein, dass eure Firewall/Virenscanner das Notebook blockiert.
Im Notebook geben wir dann in dem Eingabetextfeld mit dem blinkenden Cursor (das ist das Feld vor dem In []: steht) ein paar Zeilen Programmcode ein. Wichtig: Die Eingabe beenden wir mit UMSCHALTTASTE + EINGABETASTE (bzw. SHIFT + RETURN), also gleichzeitiges Drücken dieser beiden Tasten. Dies ist das Kommando, um den in einem Textfeld eingegebenen Programmcode auszuführen.
Versucht das einmal mit den folgenden drei Zeilen Programmcode:
%matplotlib inline
from matplotlib.pylab import *
plot([1,2,3])

Wenn alles geklappt hat, und bei Euch unter dem Programmcode mehr oder weniger dieselbe Grafik erschienen ist, dann ist die Python-Programmierumgebung, die wir verwenden werden, richtig installiert! Falls ein paar Warnmeldungen erscheinen (z.B. dass ein Font-Cache regeneriert wird oder dergleichen), dann ist das nicht weiter schlimm.
Falls nur Fehlermeldungen erscheinen und keine Grafik erscheint, dann liegt ein Problem vor. Am Wahrscheinlichsten ist, dass ihr den Programmcode falsch abgetippt habt. Habt ihr an das %-Zeichen am Anfang der ersten Zeile gedacht? Und beim plot-Befehl die eckigen Klammern innerhalb der runden Klammern nicht vergessen?
Das Nengo-Simulationspaket für neuronale Simulationen installieren¶
Nengo installieren wir über die Kommandozeile. Bei MacOS und Linux kann man ein Terminal-Fenster öffnen. Unter Linux geht das notfalls mit ALT+F2; dann in dem Anwendungsstarterfenster xterm eingeben. Dann sollte man bei Linux und MacOS in die Eingabeaufforderung eingeben:
> sudo pip install nengo
Dabei wird man zur Eingabe seines Passworts aufgefordert, die man mit der Eingabetaste abschließt. Unter Windows einfach den installierten Anaconda Command Prompt im Startmenü starten und
> pip install nengo
eingeben. In beiden Fällen sollte eine erfolgreiche Installation bestätigt werden. Die Installation können wir testen, indem wir wieder in unser Jupyter-notebook im browser wechseln (oder in der Kommandozeile einen Python-Interpreter aufrufen) und dann den Befehl:
import nengo
eingeben, der - wenn die Installation funktioniert hat, keine Fehlermeldung zurückgeben dürfte! Am besten installiert ihr auch noch eine Graphische Benutzeroberfläche für Nengo.
> pip install nengo-gui
Python lernen¶
Was jetzt folgt ist eine absolute Mini-Einführung in die Python-Programmiersprache für Leute, die noch überhaupt nie in ihrem Leben programmiert haben. Wer schon programmieren kann und bloß die Sprache Python noch nicht kennt, der sollte sich besser das Python-Tutorial docs.python.org/3/tutorial/index.html anschauen. Innerhalb eines halben Tages kann man sich damit die nötigen Grundkenntnisse leicht aneignen. Wer schon Python programmieren kann, sollte gleich zum nächsten Kapitel springen, in dem die Bedienung des Nengo-Simulationspakets in Ansätzen erklärt wird.
Grundlegende Befehle und Kontrollstrukturen¶
Das Grundprinzip der Programmierung ist sehr einfach: Man gibt dem Computer Befehle und der Computer führt sie aus. Z.B. könnten wir in das Eingabefeld den Befehl:
print("Guten Abend")
eingeben, und den Computer dann mit UMSCHALTTASTE + EINGABETASTE dazu veranlassen, den Befehl auszuführen.
print("Guten Abend")
Der print-Befehl schreibt etwas auf den Bildschirm, in diesem Fall die Worte Guten Abend. Die Anführungsstriche teilen dem Computer mit, dass er alles genau so schreiben soll, wie es zwischen den Anführungszeichen steht. Würden wir die Anführungszeichen weglassen, dann würde der Computer versuchen, das auszuwerten, was zwischen den Anführungszeichen steht. Was das bedeutet, werden wir gleich sehen.
Bekanntlich können Computer auch rechnen:
print(4 + 7)
Das Beispiel zeigt auch wozu die Ausführungszeichen vorher gut waren. Dazu noch einmal dasselbe mit Ausführungzeichen:
print("4 + 7")
Ein unerlässliches Mittel jeder Programmiersprache ist die Zuweisung von Werten (das können Zahlen, Zeichenketten oder auch irgendetwas anderes sein) zu Variablen, also z.B.:
x = 1
txt = "Eine Zeichenkette"
Diese Werte kann man jederzeit wieder auslesen, z.B. durch den print-Befehl.
print(x)
print(txt)
Man beachte, dass das Gleichheitszeichen bei der Variablenzuweisung nicht das mathematische Gleichheitszeichen ist, dass die Gleichheit zweier Werte oder beider Seiten einer Gleichung behauptet, sondern tatsächlich ein Zuweisungsoperator. Deshalb ist es auch kein Widerspruch in sich, etwas zu schreiben:
x = x + 1
Vielmehr bedeutet der Ausdruck lediglich, dass der Variablen x ihr eigener Wert um eins erhöht zugewiesen wird. Wir können das leicht prüfen:
print(x)
x = x + 1
print(x)
Um die mathematische Gleichheitsbeziehung auszudrücken verwendet man in Python das doppelte Gleichheitszeichen ==, z.B. können wir schreiben...
print(x == x + 1)
... und erhalten den Wert False, weil x ja gerade nicht gleich x + 1 ist. Das doppelte Gleichheitszeichen ist natürlich nur einer von mehreren Vergleichsoperatoren in Python. Andere Vergleichsoperatoren sind: >, >=, <, <= und !=, wobei der letzte für "ungleich" steht, diejenigen davor für "größer", "größer oder gleich", "kleiner" und "kleiner oder gleich". Mit diesem Wissen können wir den Computer einmal bis 10 zählen lassen:
x = 1
while x <= 10:
print(x)
x = x + 1
print("fertig.")
In diesem Mini-Programm tauchen noch zwei weitere Neuheiten auf: Einmal steht in zweiten Zeile ein while Befehl. Dabei handelt es sich um einen sogenannten "Schleifenbefehl". Ein Schleifenbefehl führt das, was auf den Schleifenbefehl an eingerückten Befehlen folgt, mehrfach aus - und im Ausnahmefall auch gar nicht, nur einmal oder unbegrenzt oft (Endlosschleife). Die while-Schleife führt die folgenden Befehle so oft aus, wie die angegebene Bedingung erfüllt ist.
Das zweite Element ist die Einrückung selbst. Durch Einrückung um vier Leerzeichen drückt man in Python aus, dass der Block von eingerückten Befehlen in den Kontext der unmittelbar vorhergehenden Anweisung gehört. Anweisungen, auf die ein Block folgen kann, werden immer mit einem Doppelpunkt abgeschlossen. In unseren Nengo-Simulation werden wir u.a. durch Einrückung kenntlich machen, welche Befehle in den Kontext eines bestimmten Models gehören, d.h. in diesem Fall z.B. Anweisungen, mit denen Neuronen erzeugt oder Verbindungen zwischen den Neuronen hergestellt werden. Der Block von eingerückten Befehlen endet mit dem letzten eingerückten Befehl. Im oben stehenden Beispiel gehört der Befehl print("fertig.") in der vierten Zeile nicht mehr in den Kontext der while-Schleife, denn er ist nicht mehr eingerückt, sondern befindet sich "auf derselben Ebene" wie die Schleife. Deshalb wir der letzt print-Befehl auch nur einmal ganz am Ende, nachdem die Schleife abgearbeitet worden ist, ausgeführt.
Fragen zum Ausprobieren:
- Was würde passieren, wenn man den letzten Befehl
print("fertig")auch um vier Leerzeichen einrücken würde? - Was würde passieren, wenn man den
print(x)-Befehl und die Zuweisungx = x + 1miteinander vertauscht?
Neben der while-Schleife gibt es noch einen anderen, sehr gebräuchlichen Schleifenbefehl, nämlich die for-Schleife. Mit der for-Schleife kann man eine Sequenz von Objekten (das kann eine Folge von Zahlen, eine Zeichenkette, eine Liste oder etwas anderes sein) abarbeiten. Um, wie eben, die Zahlen von eins bis zehn auszugeben, kann man mit der for-Schleife schreiben:
for x in range(1, 11):
print(x, end=" ")
Außer der for-Schleife tauchen zwei weitere Neutigkeiten in diesem Code-Fragment auf:
Die
range-Funktion: Sie liefert eine Folge (oder Präziser einen Generator für eine Folge) von Zahlen zurück, in diesem Fall die Zahlen von 1 bis einschließlich 10. Dass in der entsprechenden Zeile die Zahl 11 statt 10 steht, hat damit zu tun, dass man bei derrange-Funktion immmer das halboffene Intervall angibt, d.i. das Intervall, welches den ersten angegebenen Wert miteinschließt, aber nicht mehr den letzten.Dem
print-Befehl wurde diesmal ein Wert für den benannten Parameterendmitgegeben. In Python werden die Parameter eines Befehls oder einer Funktion in der Regel durch ihre Position bestimmt, d.h. es gibt den ersten, den zweiten, den dritten Parameter usw. Daneben kann man aber auch explizit den Namen eines Parameters angeben, um ihm einen Wert zu übergeben. Das empfiehlt sich besonders dann, wenn eine Funktion eine lange Liste von möglichen Parametern kennt, und man nur bestimmte Parameter festlegen möchte, während man bei den anderen die default-Werte beibehalten möchte. Um zu erfahren, welche Parameter eine Funktion überhaupt kennt, kann man den Befehllhelp(FUNKTIONSNAME)eigeben, also z.B.help(print). (Quizfrage: Was bedeutet und welchen default-Wert hat derend-Parameter der Funktionprint? Verstehst Du jetzt, weshalb die Zahlen nach einander und nicht wie in dem vorigen Beispiel untereinander ausgegeben wurden?) Die meisten größeren Programmpakete, und so auch Nengo, machen ziemlich exzessiv von der Möglichkeit benannter Parameter Gebrauch.
Die Besonderheit der for-Schleife besteht darin, dass sie eine Schleifenvariable hat, die auf das Wort for und vor dem in folgt. Die Schleifenvariable nimmt bei jedem folgenden Durchlauf der Schleife einen weiteren Wert aus der durchlaufenen Sequenz an. Man muss sich also, anders als bei der while-Schleife nicht selbst um das setzen des Anfangswertes und die Änderung der Schleifenvariable kümmern.
Ein weiterer wichtiger Befehl, der in fast keinem Python-Programm fehlt, ist der if-Befehl. if prüft, ob eine Bedingung erfüllt ist und führt den folgenden eingerückten Block nur dann aus, wenn das der Fall ist. Beispiel:
eingabe = input("Wie heisst Du? ")
if len(eingabe) > 5:
print("Das ist aber ein langer Name!")
Der len-Befehl gibt übrigens, wie man sich denken kann, die Länge einer Zeichenkette, d.i. die Anzahl ihrer Zeichen zurück. Der input-Befehl ist das Gegenstück zum print-Befehl. Er bittet den Nutzer um eine Eingabe. Eine sehr praktische Eigenschaft von Python ist, dass man Befehle oder Funktionen auch selbst definieren kann. (In Python sind Befehle und Funktionen übrigens mehr oder weniger dasselbe, während sie in anderen Programmiersprachen manchmal dadurch unterschieden werden, dass nur Funktionen einen Rückgabewert haben dürfen.) Das geschieht mit der def-Anweisung:
def quersumme(zahl):
ziffern = str(zahl)
summe = 0
for zeichen in ziffern:
summe = summe + int(zeichen)
return summe
print("Die Quersumme von 385 ist:")
print(quersumme(385))
Auf das Schlüsselwort def folgt der Befehles bzw. Funktionsname und dann in Klammern eine Liste von Parametern. Was die Funktion tut, folgt in einem eingerückten Block. Eine Funktion kann, muss aber nicht unbedingt einen Wert zurückgeben. Die Rückgabe eines Wertes geschieht mit dem return-Befehl. Die Definition der Funktion ist abgeschlossen, sobald eine Zeile folgt, die nicht mehr eingerückt ist.
Die for-Schleife kann man übrigens, wie man sieht, auch dazu nutzen, um die Zeichen einer Zeichenkette zu durchlaufen. Die Zahl deren Quersumme berechnet wird, wird daher mittels des str-Befehls (str für string = Zeichenkette) in eine Zeichenkette umgewandelt. Da man Zeichen nicht addieren kann, werden die Ziffern der Zahl vor der Bildung der Summe mit dem int-Befehl (int für integer = Ganzzahl) in Zahlen umgewandelt.
Eine sehr praktische Eigenschaft ist, dass man selbstdefinierte Funktionen in sogenannten Modulen ablegen und in andere Programme importieren kann. Damit lässt sich die Menge der Python bekannten Befehle und Funktionen praktisch beliebig erweitern. Das importieren geschieht mit der import-Anweisung. Python kennt zum Beispiel keinen Befehl, mit dem man Zufallszahlen erzeugen kann. Aber man kann ein Modul für Zufallszahlen importieren und daraus einen Befehl aufrufen, der Zufallszahlen erzeugt:
import random
r = random.random()
print(r)
Mit import MODULNAME importiert man ein Modul. Um einen Befehl aus einem Modul aufzurufen, schreibtman MODULNAME.BEFEHLSNAME. In dem Beispiel wird der Befehl random aus dem Modul random aufgerufen, der eine Zufallszahl zwischen 0.0 und 1.0 erzeugt. Varianten des import Befehls sind:
from MODUL import NAME
Diese Variante erlaubt es einen Namen zu verwenden, ohne dass immer das Modul angegeben werden muss. Und:
import MODUL as KÜRZEL
Die Variante mit as erlaubt es den Modulnamen durch ein Kürzel zu ersetzen, .z.B.:
import random as rnd
rnd.random()Das bisher Gelernte können wir nun in Form eines kleinen Beispiel-Programms ausprobieren. Bei dem Programm geht es darum, in möglichst wenigen Schritten eine vom Computer zufällig gewählte Zahl zu erraten. Diesen bedeutenden Klassiker fortgeschrittener Programmierkunst findet man übrigens schon im C64-Handbuch, auf Seite 51 ;-)
def zahlenraten(obergenze = 100):
print("Zahlenraten")
obergrenze = 100
print("Rate meine Geheimzahl zwischen 1 und 100!")
zahl = random.randint(1, 100)
geraten = 0
while geraten != zahl:
eingabe = input("Bitte gib eine Zahl ein: ")
geraten = int(eingabe)
if zahl > geraten:
print("Meine Zahl ist größer!")
elif zahl < geraten:
print("Meine Zahl ist kleiner!")
else:
print("Toll, Du hast die Zahl erraten!")
In diesem Beispiel ist übrigens für den Parameter obergrenze der Funktion Zahlenraten ein Vorgabewert angegeben, d.h. man braucht für den Parameter obergrenze keinen Wert anzugeben, sofern man mit dem Vorgabewert einverstanden ist.
Aus dem Modul random wurde diesmal eine andere Funktion, nämlich randint gewählt, die ganzzahlige Zufallswerte innerhalb eines bestimmten Bereichs liefert. Die Bedeutung der Anweisungen elif und else kann man sich fast denken. Der auf else: folgende Block wird dann aus geführt, wenn die vorhergehende(n) Bedingung(en) falsch gewesen sind. elif ist eine Kurzform für "else if", d.h. eine else-Klausel, auf die gleich wieder eine if-Klauses folgt. Diese Form der verketteten if... elif... elif ... ... else...-Anweisungen ist recht typisch bei der Verwendung des if-Befehls.
zahlenraten()
Wichtige Python-Datentypen¶
Die Einführung eben konnten natürlich nur einen kleinen Teil der Python-Sprache vorstellen, aber sie hat hoffentlich vor Augen geführt, wie programmieren funktioniert. Bevor wir uns Nengo anschauen, sollen aber noch einige der wichtigsten Datentypen von Python vorgestellt werden, da sie auch in Nengo gebraucht werden.
Zwei Datentypen kennen wir bereits, nämlich (ganze) Zahlen und Zeichenketten. Ein weiterer wichtiger Datentyp ist die Liste. Die Zuweisung
l = [1, 2, 3]
definiert eine Liste der Zahlen eins bis drei. Listen müssen nicht zwangsläufig Elemente ein und desselben Typs enthalten. Vielmehr ist:
l = [1, "Haus", 3]
genauso eine Liste. Listen erlauben es, einzelne Listen elemente auszulesen, Bereiche von Listen ("slices") auszuwählen, Elemente an eine Liste anzuhängen, Elemente zu löschen und Listen zu verketten:
l = list(range(0,10))
print(l)
l.append(10) # anhängen eines einzelnen Elements
print(l) # Übrigens, alles was in einer Zeile auf das #-Zeichen folgt,
# ist in Python ein Kommentar
del l[5] # löschen des 5. Elements; merke: die Indizes werden immer von 0 gezählt!
print(l)
l.insert(5, "Haus") # einfügen eines Elements, vor einem bestimmten Index
print(l)
l[5] = 5 # ersetzen eines bestimmten Elements durch ein anderes
print(l)
k = l[2:5] # Herauskopieren eines Teils der Liste;
# merke: wie bei range() wird immer das halboffene Intervall angegeben!
print(k)
Listen sind ausgesprochen flexible Objekte. Manchmal ist diese Felxibilität aber gar nicht erwünscht. Möchte man z.B. einen mathematischen Vektor in Python beschreiben, dann könnte man zwar eine Liste verwenden, aber da ein Vektor nur aus Zahlen besteht, wäre es wünschenswert, wenn auch die Elemente eines Vektors auch nur Zahlen sein könnten, damit man zumindest eine Fehlermeldung bekommt, wenn man versehentlich "Haus" oder etwas ähnlich Falsches zuweisen möchte. Dafür ist der Datentyp Array weit besser geeignet. Dieser Datentype ist nicht in Python enthalten, sondern muss auss dem Numpy-Paket importiert werden:
import numpy
v = numpy.array([0,1,2])
print(v)
v[1] = "Haus" # --> ValueError, da arrays nur Daten eines Typs umfassen können!
Mit Hilfe von Arrays kann man auch Matrizen (als 2-Dimensionale Arrays) zusammensetzen:
m = numpy.array([[1,2,3],[4,5,6],[7,8,9]])
print(m)
Arithmetische Operationen laufen bei arrays immer Elementweise ab. Der folgende Befehl liefert also keine Matrixmultiplikation!
m * m
Für die Matrix-Multiplikation gibt es allerdings seit Python Version 3.5 einen besonderen Operator, nämlich '@':
m @ v
Als letztes soll noch kurz auf Objekt-Typen eingegangen werden. In Python ist jeder Wert immer auch ein Objekt (Python ist eine sogenannte "objektorientierte" Sprache, aber das soll hier nicht vertieft werden) und man kann auch eigene Objekt-Klassen definieren, die aus anderen Objekt-Klassen abgeleitet werden. Genau auf diese Weise wird in dem numpy-Modul übrigens der array-Datentyp definiert. Die Definition neuer Objekt-Klassen zu erläutern würde hier zu weit führen, aber er soll gezeigt werden, wie man Objekte anwendet. Das besondere an Objekten ist, dass man auf ihnen bestimmte Methoden ausführen kann. Die Notation ist ähnlich wie beider Ausführung von Funktionen, die zu einem bestimmten Modul gehören und folgt immer dem Schema:
OBJEKTNAME.METHODENNAME(PARAMETER)
Dazu als Beispiel die Methode find, die für alle Zeichenketten-Objekte definiert ist. Find liefert die Position des ersten Zeichens einer Teilzeichenkette zurück:
"Bedecke Deinen Himmel, Zeus, mit Wolkendunst".find("Zeus")
Welche Methoden ein Objekt bereit hält, kann man übrigens mit dem Befehl dir herausfinden. Die Bedeutung einer Methode kann man wiederum mit dem help-Befehl erfragen:
help("Bedecke...".find)
Das Erzeugen von komplexeren Objekten sieht in Python fast genauso aus, wie ein ein Funktionsaufruf. Dies sei am Beispiel eines Datumsobjekts vor Augen geführt:
from datetime import date
datum = date(2015, 2, 19)
print(datum)
print(type(datum))
Die type-Funktion liefert übrigens immer den Typ bzw. die "Klasse" eines Objekts zurück. Sie wurde hier verwendet, um zu demonstrieren, dass die Variable datum auch tatsächlich ein Objekt des Typs date enthält und date nicht etwa einfach eine Funktion ist, die einen String zurückgibt.
Simulationen mit Nengo bauen¶
Zuletzt wollen wir an einem einfachen Beispiel zeigen, wie man mit nengo eine Simulation baut.
Die Mini-Programme, die wir bisher geschrieben haben, haben wir in einem imperativen Stil programmiert, d.h. der Computer bekommt Anweisungen, die er nacheinander ausführt und am Ende wird ein Ergebnis ausgegeben. Wenn man mit Nengo Simulationen realisiert, dann bedient man sich eher eines deklarativen Programmierstiels. Der Computer arbeit dabei zwar immer noch eine Reihe von Anweisungen ab, aber die meisten dieser Anweisungen beschreiben eher einen Zusammenhang von Objekten, in diesem Fall meist Ensembles von Neuronen und deren Verbindungen, und am Ende wird durch ein Kommando eine Simulation darauf gestartet.
Als Beispiel vollziehen wir hier das Kommunikations-Kanal-Beispiel aus der Nengo-Einführung heran. Bevor wir deklarativ den Aufbau der Simulation beschreiben, müssen wir zunächst einige Module importieren, die wir benötigen:
import numpy as np
import nengo
Kommt es an dieser Stelle zu einer Fehlermeldung, dann stimmt irgendetwas mit der Installation nicht. Insbesondere die Installation von nengo (s.o.) könnte schief gegangen oder noch gar nicht statt gefunden haben.
model = nengo.Network(label="Ein einfacher Kommunikationskanal")
Als erstes wird ein neues, leeres Modell erzeugt (s.o.). In dem Kontext dieses Modells werden im Folgenden ein Eingabesignal, zwei Gruppen von Neuronen und je eine Verbindung zwischen dem Eingangssignal und der ersten Gruppe und dann zwischen der ersten und der zweiten Gruppe definiert:
with model:
signal = nengo.Node(np.sin)
A = nengo.Ensemble(100, dimensions=1)
B = nengo.Ensemble(100, dimensions=1)
nengo.Connection(signal, A)
nengo.Connection(A, B)
Damit ist das Modell bereits fertig definiert. Es handelt sich um ein recht triviales Model. Das Eingabesignal ist eine einfache Sinusfunktion. Die beiden Gruppen von Neuronen bestehen aus jeweil 100 Neuronen, die ein ein-dimensionales Signal repräsentieren. (Die ganze Gruppe von Neuronen repräsentiert als Gruppe das Signal.) Ein-dimensional heisst in diesem Zusammenhang, die Gruppe von Neuronen repräsentiert einen einfachen Zahlenwert im Gegensatz etwa zu einem Vektor. Dieser Zahlenwert kann natürlich, wie wir gleich in der Ausgabe sehen werden, immer noch mit der Zeit variieren.
Im nächsten Schritt, legen wir fest, welche (änderbaren Größen) innerhalb unseres Modell-Systems wir beobachten wollen. Dazu werden sogenannte Probe-Objekte angelegt.
with model:
signal_probe = nengo.Probe(signal)
A_probe = nengo.Probe(A, synapse=.0)
B_probe = nengo.Probe(B, synapse=.0)
Wie man sieht wird beim Anlegen der Probe-Objekte jeweils das beobachtete Objekt als Parameter übergeben. Der synapse-Parameter legt hierbei einen Schwellenwertfest für das Ausgangssignal an den Kontaktstellen der Neuronen definiert, das andernsfalls stark verrauscht erscheinen kann. [@Ralf und Philipp: STIMMT DAS EINIGERMAßEN?]
Sind die Beobachter- bzw. Probe-Objekte festgelegt, dann können wir auf dem Modell eine Simulation laufen lassen, indem wir ein Simulations-Objekt anlegen und auf dem Simulationsobjekt die run-Methode ausführen. An die run-Methode müssen wir einen Parameter übergeben, der den zu simulierenden Zeitraum in Sekunden festlegt:
sim = nengo.Simulator(model)
sim.run(10)
Die Simulation selbst kann, je nach Geschwindigkeit des verwendeten Rechners, natürlich länger dauern als der simulierte Zeitraum! Ist die Simulation abgelaufen, dann können wir die Ergebnisse grafisch anzeigen lassen. Dazu bedienen wir uns eines Moduls aus der matplot-Bibliothek, die mit Anaconda mitinstalliert worden sein sollte:
import matplotlib.pyplot as plot
%matplotlib inline
plot.figure(figsize=(9, 3))
plot.subplot(1, 3, 1)
plot.title("Input")
plot.plot(sim.trange(), sim.data[signal_probe])
plot.ylim(0, 1.2)
plot.subplot(1, 3, 2)
plot.title("A")
plot.plot(sim.trange(), sim.data[A_probe])
plot.ylim(0, 1.2)
plot.subplot(1,3,3)
plot.title("B")
plot.plot(sim.trange(), sim.data[B_probe])
plot.ylim(0, 1.2)

Man sieht, wie das Eingangssignal im zeitlichen Verlauf von der Neuronengruppe A aufgegriffen worden ist und wie es von der Neuronengruppe B nach der Übertragung wiedergegeben wird.
In der zweiten Zeile des Programms handelt es sich bei %matplotlib inline übrigens nicht um einen Python-Befehl, sondern um eine Direktive für die Jupyter-Notebook-Umgebung, die das Jupyter-notebook anweist, die grafischen Ausgaben der matplot-Bibliothek innerhalb des fortlaufenden Textes des notebooks und nicht in einem eigenen Fenster anzuzeigen.
Kleine Aufgabe für Ehrgeizige: Ändert die Simulation so ab, dass das Signal über mehrere Schritte übertragen wird. Wie wirkt sich das am Ende auf die Signalqualität aus?
Damit wären wir am Ende unserer Einführung. Wir hoffen, es hat Spaß gemacht!
Philipp, Ralf und Eckhart